DeepSeek Launches V4 API: Flash and Pro Versions
DeepSeek V4 has finally been released!
The long-awaited preview version of DeepSeek V4 has officially debuted, featuring two versions—V4-Pro and V4-Flash, both equipped with a standard 1M (one million words) long context, alongside open-source model weights and technical reports.
In the days leading up to the May Day holiday, the large model landscape has seen a new wave of releases.
On April 23, Tencent’s genius model, Hy3, was unveiled, boasting a 295 billion parameter MoE architecture, with 21B active parameters and a 40% increase in inference efficiency, while reducing input costs to 1.2 yuan per million tokens.
Earlier today, OpenAI launched GPT-5.5 for paid users and announced its API plans, focusing on agent workflows and multi-step task completion, with a context window extended to 1 million tokens. The API pricing has also risen significantly—5 dollars for input and 30 dollars for output per million tokens.
At first glance, the three companies are taking different paths: OpenAI continues its high-end closed-source approach while raising prices; Tencent integrates its model into its ecosystem, leveraging cost-effectiveness for large-scale commercial use; DeepSeek maintains its open-source tradition while pushing context length to a new inclusive threshold.
Key Features of DeepSeek V4
DeepSeek’s release has transformed the one million word context from a “high-end option” to a “basic standard.”
Previously, a 1M context length was typically found in high-end versions of flagship closed-source models, with prohibitive usage costs that deterred most developers and small to medium enterprises.
DeepSeek’s approach is clear: both V4-Pro and V4-Flash versions come standard with 1M context length, with the former targeting peak performance and the latter offering an economical choice, fully covering different user needs. This strategy of “universal allocation of core capabilities” fundamentally lowers the barriers for accessing long text processing capabilities in the industry.

The Flash version emphasizes ultra-low latency and high cost-effectiveness, providing a core solution for lightweight high-frequency scenarios. With 13B active parameters, a new token compression attention mechanism, and DSA sparse attention architecture optimization, it achieves rapid response times while maintaining performance close to the Pro version’s core inference capabilities. This feature significantly enhances the experience for real-time dialogue interactions, function call pipelines, and any lightweight scenarios sensitive to response speed.
Competitive Cost Structure
According to DeepSeek’s official API pricing documentation, the Flash version employs a tiered billing model: cached input tokens are as low as 0.2 yuan per million tokens, uncached input tokens are 1 yuan per million tokens, and output tokens are priced at 2 yuan per million tokens.
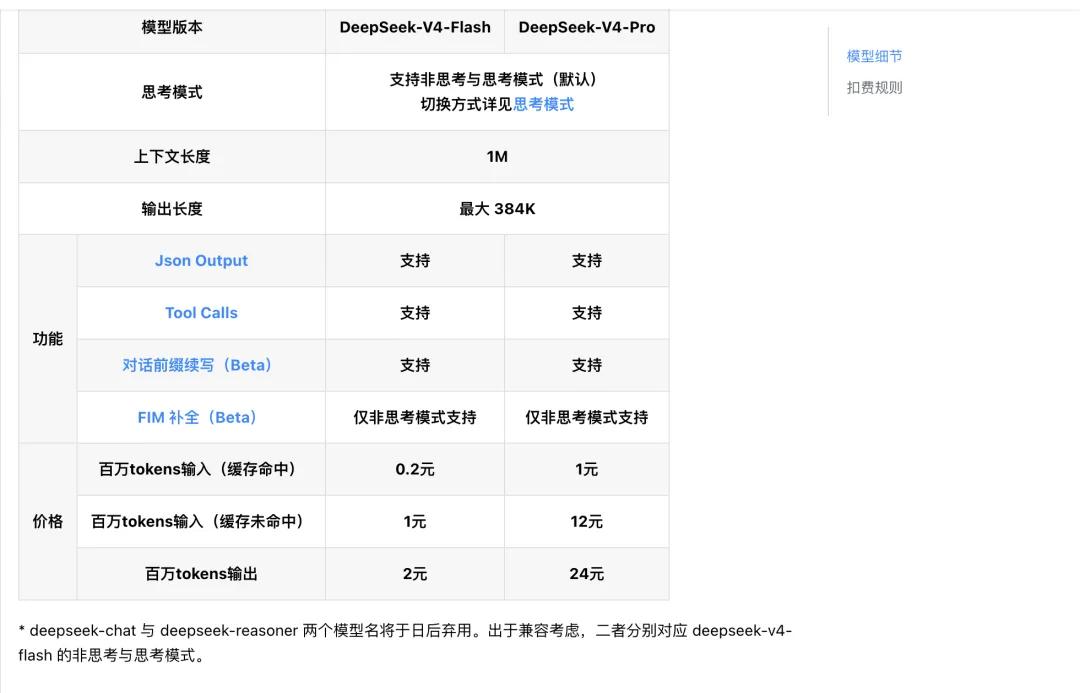
This user-friendly pricing, combined with the standard 1M context capability, means that the “cost per call” is no longer a core constraint in engineering design—developers can prioritize product experience and architectural design without repeatedly weighing call frequency against costs.
Flash addresses the need for “affordable and fast” solutions, while V4-Pro answers the question of how far the capabilities of open-source large models can be pushed.
The most intuitive capability leap revolves around long context. DeepSeek has increased the model’s context length from the previous generation V3.2’s 128K to 1M (one million tokens), significantly reducing the computational and memory requirements for long context while ensuring performance remains intact across the entire context window.
At this scale, developers can directly import complete codebases, lengthy industry documents, multi-round project archives, or even entire books of a million words for end-to-end processing without needing to build complex retrieval-augmented generation (RAG) systems, greatly simplifying the technical pathway for long text processing.
On the architectural level, the Pro version utilizes a total parameter count of 1.6T and 49B active parameters in a MoE architecture, with a pre-training data volume of 33T, representing a comprehensive deepening of DeepSeek’s mixed expert approach. Official evaluation data shows it surpasses all publicly evaluated open-source models in core reasoning assessments in mathematics, STEM, and competitive coding, reaching levels comparable to the world’s top closed-source models.
Agent Capabilities
In terms of agent capabilities, its delivery quality is nearing that of Claude Opus 4.6 in non-thinking mode, with internal feedback exceeding that of Anthropic Sonnet 4.5, making it a primary agent coding tool among DeepSeek employees.
Both versions of the V4 series support non-thinking and thinking modes, allowing developers to customize reasoning intensity through the reasoning_effort parameter, while fully supporting Json Output, Tool Calls, and dialogue prefix continuation capabilities.
Pricing for the Pro version continues the cost-effective route, with official pricing set at: 1 yuan per million tokens for cached input, 12 yuan per million tokens for uncached input, and 24 yuan per million tokens for output, significantly lower than similar flagship closed-source models abroad.
API integration has been made extremely accessible; developers need only to replace the model parameter with the corresponding version name without modifying the original base_url, while also being compatible with both OpenAI ChatCompletions and Anthropic interface formats.
This combination of “capability enhancement + cost reduction” ensures that top-tier large model capabilities are no longer exclusive to a few vendors. As the industry becomes increasingly embroiled in a parameter arms race, DeepSeek’s offering of universally equipped million-context and fully open-source options provides a new model for democratizing large models.
Additionally, DeepSeek V4 has been specifically adapted and optimized for mainstream agent products like Claude Code, OpenClaw, OpenCode, and CodeBuddy, showing improved performance in scenarios such as coding tasks and document generation. The model’s value ultimately needs to be validated in real development and workflow applications.
Continuing Open Source with Full API Access
DeepSeek continues its open-source path and has fully opened API access.
Currently, the model weights for DeepSeek-V4 are available for download on Hugging Face and ModelScope platforms, along with accompanying technical reports, supporting developers in local deployment and secondary development.
Unlike some vendors’ practices of offering “cut-down open-source versions and full closed-source versions,” both open-source versions this time retain all capabilities consistent with the official cloud API—including non-thinking/thinking dual modes, 1M ultra-long context lossless processing, agent-specific optimizations, and full tool calling capabilities, with no functional reductions.
This means that whether for small startups, individual developers, or research institutions, they can access the foundational model with million-context, top-tier reasoning, and agent capabilities without paying high fees for closed-source interfaces.
To further reduce entry barriers, DeepSeek has also open-sourced the entire toolchain for model fine-tuning, quantization, and inference acceleration, completing Day 0 native adaptations for mainstream inference frameworks like vLLM and TGI, as well as agent frameworks like LangChain and LlamaIndex, while providing a full-stack deployment solution for domestic computing platforms, enabling developers to quickly implement applications across different hardware environments.
Meanwhile, DeepSeek has outlined a clear transition plan for model iterations: the old API interface model names deepseek-chat and deepseek-reasoner will cease to be used three months later (July 24, 2026). Currently, these two model names point to the non-thinking and thinking modes of deepseek-v4-flash, respectively, allowing developers ample time for a smooth transition.
Committed to Being an AI Infrastructure Model
Looking at the recent releases, a clear trend emerges: companies are accelerating their agent capabilities.
Over the past two years, public and capital market attention on large models has largely focused on their “intelligence level,” but now it has shifted to “who can reliably get things done.” The release of GPT-5.5 emphasizes not how much multimodal understanding has improved, but its sustained execution capabilities in agent programming, computer usage, and knowledge work scenarios. Tencent’s Hy3 also highlights its “action capabilities” in the real world. DeepSeek V4 directly promotes agent capabilities and long context processing as its main features, clearly targeting actual workloads.
This shift reflects the industry’s move towards competition in “model utility.” Users and enterprise clients are increasingly less concerned about where your model ranks in evaluations; they care about how well the model and product can help them get their tasks done: can this model help me write code, handle complex documents, manage multi-step tasks without errors, and operate at a reasonable cost?

At the end of today’s announcement, DeepSeek quoted a line from Xunzi: “Do not be swayed by praise, nor be afraid of slander; follow the path and correct oneself.” This continues to anchor its technological direction. In the current competitive landscape of large models, this statement carries a clear meaning—do not be disturbed by external evaluations and noise, but focus on doing things right.
DeepSeek’s actions over the past year have indeed practiced this logic: building global developer ecosystem influence through open-source openness, breaking down barriers to high-end AI capability usage with extreme cost-effectiveness, and addressing the most genuine pain points of developers and enterprise users through solid underlying architectural innovation.
From the emergence of the R1 inference model to V4 pushing long context capabilities into an inclusive range for the first time, DeepSeek has consistently pursued a relatively “slow” approach to accomplish a more challenging task—transforming top-tier model capabilities from tools for a few into infrastructure that more people can directly access.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.